

Python Project: Analyze Text with Python
Level: Beginner

Project Overview 💡
In this project, you'll build a simple text analyzer in Python. You'll learn how to process text, count words, sentences, and characters, and identify the most frequent word. This is a great exercise in string manipulation and working with dictionaries.
Challenge Yourself! 🚀
Before looking at the solution, try to solve this problem on your own!
Task:
Write a Python script that takes a user-inputted block of text and analyzes it by calculating the number of characters, words, and sentences. Additionally, determine the most frequently used word and calculate the average word and sentence length.
Expected Output:
The program should output text statistics, including:
Total Characters
Total Words
Total Sentences
Most Frequent Word
Average Word Length
Average Sentence Length
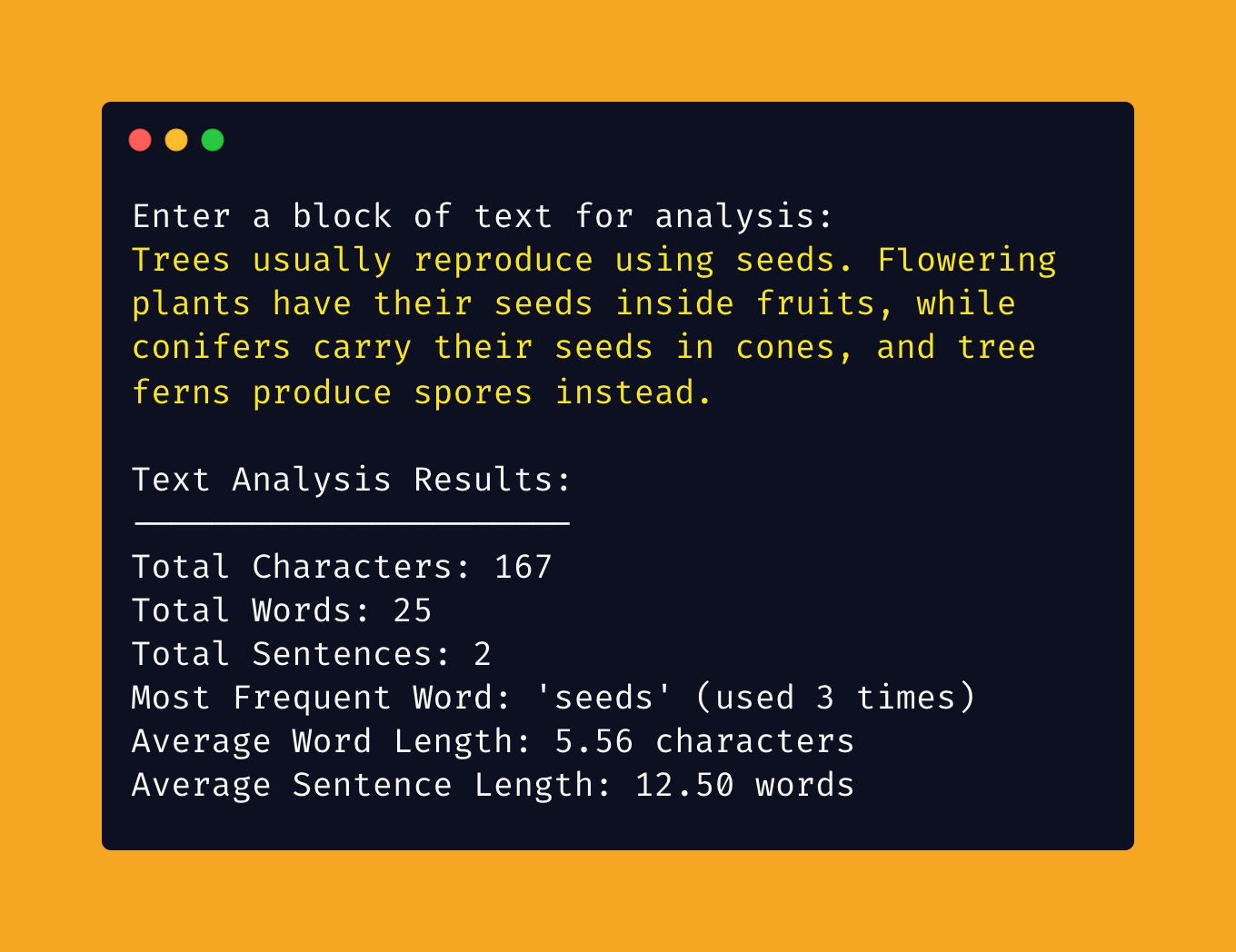
Here is a demo of the program. The user has typed in the sentence shown in the yellow text and the program prints out the statistics.
Try it first! When you're ready, follow the step-by-step guide below.
Spoiler Alert!
Step-by-Step Guide
Step 1️⃣: Get User Input
First, prompt the user to enter a block of text for analysis.
Place this code in line 1-2:
# Step 1: Get user input
text = input("Enter a block of text for analysis:\n")Step 2️⃣: Initialize Counters and Storage
Next, initialize variables to store character, word, and sentence counts, as well as a dictionary to track word frequencies.
Place this code in lines 4-8:
# Step 2: Initialize counters and storage
character_count = len(text)
word_count = len(text.split())
sentence_count = text.count('.') + text.count('!') + text.count('?')
word_frequency = {}Step 3️⃣: Define a Function to Remove Punctuation
Create a helper function to remove punctuation from the text.
Place this code in lines 10-15:
# Step 3: Define a function to remove punctuation
def remove_punctuation(s):
punctuation = ".,!?:;'\"()[]{}"
for char in punctuation:
s = s.replace(char, "")
return sStep 4️⃣: Analyze the Text
Remove punctuation, convert the text to lowercase, and populate the word frequency dictionary.
Place this code in lines 17-22:
# Step 4: Analyze the text
cleaned_text = remove_punctuation(text).lower()
words = cleaned_text.split()
for word in words:
word_frequency[word] = word_frequency.get(word, 0) + 1Step 5️⃣: Calculate Additional Statistics
Find the most frequent word and calculate the average word and sentence lengths.
Place this code in lines 24-32:
# Step 5: Calculate additional statistics
if word_count > 0:
most_frequent_word = max(word_frequency, key=word_frequency.get)
average_word_length = sum(len(word) for word in words) / word_count
average_sentence_length = word_count / sentence_count if sentence_count > 0 else word_count
else:
most_frequent_word = None
average_word_length = 0
average_sentence_length = 0Step 6️⃣: Display the Results
Finally, print the results of the analysis.
Place this code in lines 34-45:
# Step 6: Display the results
print("\nText Analysis Results:")
print("-" * 22)
print(f"Total Characters: {character_count}")
print(f"Total Words: {word_count}")
print(f"Total Sentences: {sentence_count}")
if most_frequent_word:
print(f"Most Frequent Word: '{most_frequent_word}' (used {word_frequency[most_frequent_word]} times)")
print(f"Average Word Length: {average_word_length:.2f} characters")
print(f"Average Sentence Length: {average_sentence_length:.2f} words")Complete Code 🧨
# Step 1: Get user input
text = input("Enter a block of text for analysis:\n")
# Step 2: Initialize counters and storage
character_count = len(text)
word_count = len(text.split())
sentence_count = text.count('.') + text.count('!') + text.count('?')
word_frequency = {}
# Step 3: Define a function to remove punctuation
def remove_punctuation(s):
punctuation = ".,!?:;'\"()[]{}"
for char in punctuation:
s = s.replace(char, "")
return s
# Step 4: Analyze the text
cleaned_text = remove_punctuation(text).lower()
words = cleaned_text.split()
for word in words:
word_frequency[word] = word_frequency.get(word, 0) + 1
# Step 5: Calculate additional statistics
if word_count > 0:
most_frequent_word = max(word_frequency, key=word_frequency.get)
average_word_length = sum(len(word) for word in words) / word_count
average_sentence_length = word_count / sentence_count if sentence_count > 0 else word_count
else:
most_frequent_word = None
average_word_length = 0
average_sentence_length = 0
# Step 6: Display the results
print("\nText Analysis Results:")
print("-" * 22)
print(f"Total Characters: {character_count}")
print(f"Total Words: {word_count}")
print(f"Total Sentences: {sentence_count}")
if most_frequent_word:
print(f"Most Frequent Word: '{most_frequent_word}' (used {word_frequency[most_frequent_word]} times)")
print(f"Average Word Length: {average_word_length:.2f} characters")
print(f"Average Sentence Length: {average_sentence_length:.2f} words")Enjoyed this project? Unlock real-world projects with full guides & solutions by subscribing to the paid plan.
I couldnt figure out how to handle abbreviations (Dr., St., etc) without using an nlp model like spacy or nltk. Is there a simpler approach?